本文将为 SEO 从业者全面解析大语言模型、自然语言处理及相关领域的核心知识,解答你心中的疑问:该不该用大语言模型做关键词研究?这些模型真的有思考能力吗?ChatGPT 是助力工具还是潜在风险?
一、大白话解读大语言模型、自然语言处理及相关概念
想让一个人做事,无非两种方式:直接吩咐,或寄希望于其自觉行动。
对应到计算机科学领域,编程就是 “直接吩咐机器人做事”,而机器学习则是 “让机器人自主尝试做事”—— 前者属于监督式机器学习,后者为无监督式机器学习。
自然语言处理(NLP)是一种将文本转化为数字形式,再通过计算机进行分析的技术。
计算机会先分析词汇中的规律,技术进阶后,还能解读词汇之间的关联。
无监督式自然语言机器学习模型可在多种数据集上完成训练:
比如,用《水世界》的普通影评训练语言模型,它就能擅长撰写或理解这部电影的影评;
但如果仅用我写的两篇《水世界》正面影评训练,它就只能理解这类正面评价。
大语言模型(LLM)是拥有超 10 亿参数的神经网络,因其规模庞大,具备更强的泛化能力。它的训练数据不仅包括《水世界》的正负影评,还涵盖网络评论、维基百科词条、新闻网站内容等海量信息。
机器学习项目高度依赖上下文,既包括相关上下文,也涉及无关干扰信息。
比如,一个用于识别程序漏洞的机器学习模型,若给它输入一张猫咪图片,它完全无法处理 —— 自动驾驶技术的研发难度也正源于此:现实中存在大量无关联的干扰问题,让模型的知识泛化变得异常困难。
大语言模型看似且实际比其他机器学习项目的泛化能力更强,核心原因在于其训练数据量的绝对规模,以及对数十亿种词汇关联的处理能力。
接下来,我们就来聊聊支撑这一能力的核心技术 ——Transformer 架构。
二、从头解析 Transformer 架构
Transformer 是一种神经网络架构,彻底革新了自然语言处理领域。
在 Transformer 出现前,绝大多数自然语言处理模型依赖循环神经网络(RNN),这类模型会逐词顺序处理文本,存在速度慢、难以捕捉文本长距离关联的缺陷。
Transformer 彻底改变了这一现状。
2017 年,瓦斯瓦尼等人在里程碑式论文《注意力就是一切》(Attention is All You Need)中,首次提出了 Transformer 架构。
与循环神经网络的顺序处理不同,Transformer 通过自注意力机制并行处理所有词汇,能更高效地捕捉文本的长距离关联。
此前的主流架构还包括循环神经网络和长短期记忆算法,这类循环模型至今仍被用于文本、语音等序列数据相关任务。
但它们的固有问题十分明显:只能逐段处理数据,不仅速度慢,还限制了可处理的数据量,这种顺序处理模式极大制约了模型能力。
注意力机制的出现,为序列数据处理提供了新路径:它让模型能同时分析所有数据,并判断各部分的重要性,在诸多任务中发挥了重要作用。但此前的多数模型虽引入了注意力机制,仍保留了循环处理模式 —— 简单来说,这些模型能同时分析数据,却仍需按顺序解读。而瓦斯瓦尼等人的论文提出了一个全新思路:如果只使用注意力机制,会带来怎样的效果?
注意力机制的核心,是让模型处理输入序列时,聚焦于关键部分。就像人类阅读句子时,会根据上下文和理解需求,自然地将注意力放在部分词汇上。
具体到 Transformer 模型,它会为输入序列中的每个词汇计算重要性得分,得分高低取决于该词汇对理解整段文本含义的作用。
随后,模型会根据这些得分给每个词汇赋予不同权重,让重要词汇获得更多关注,次要词汇则被弱化。
这一机制让模型无需逐词顺序处理全文,就能捕捉到文本中距离较远的词汇间的关联和依赖,也正因如此,Transformer 在自然语言处理任务中表现出强大能力,能快速、准确地理解单句甚至长文本的含义。
我们以 Transformer 处理句子 **“The cat sat on the mat.(猫坐在垫子上)”为例,直观理解其工作原理:首先,模型会通过嵌入矩阵 **,将每个词汇转化为由一系列数字组成的向量,假设各词汇的向量表示为:
- 定冠词 The:[0.2, 0.1, 0.3, 0.5]
- 猫 cat:[0.6, 0.3, 0.1, 0.2]
- 坐 sat:[0.1, 0.8, 0.2, 0.3]
- 在 on:[0.3, 0.1, 0.6, 0.4]
- 定冠词 the:[0.5, 0.2, 0.1, 0.4]
- 垫子 mat:[0.2, 0.4, 0.7, 0.5]
接着,模型会通过计算向量点积,为每个词汇计算其与句中其他所有词汇的关联得分。
以计算 “cat(猫)” 的关联得分为例,需将其向量与其他所有词汇的向量分别做点积运算:
- The 和 cat:0.2×0.6 + 0.1×0.3 + 0.3×0.1 + 0.5×0.2 = 0.24
- cat 和 sat:0.6×0.1 + 0.3×0.8 + 0.1×0.2 + 0.2×0.3 = 0.31
- cat 和 on:0.6×0.3 + 0.3×0.1 + 0.1×0.6 + 0.2×0.4 = 0.39
- cat 和 the:0.6×0.5 + 0.3×0.2 + 0.1×0.1 + 0.2×0.4 = 0.42
- cat 和 mat:0.6×0.2 + 0.3×0.4 + 0.1×0.7 + 0.2×0.5 = 0.32
这些得分代表着其他词汇与 “cat(猫)” 的关联程度,模型会以这些得分为权重,计算所有词汇向量的加权和,最终生成 “cat(猫)” 的上下文向量—— 这一向量整合了该词与句中所有词汇的关联。模型会对句中每个词汇重复这一过程。
你可以将其理解为:Transformer 会根据每一次的计算结果,在句中各词汇间建立关联,关联的强弱由得分决定,部分关联紧密,部分则较为微弱。
Transformer 是首个纯依赖注意力机制、摒弃循环处理的模型,这让它的处理速度大幅提升,且能处理更多数据。
三、GPT 如何运用 Transformer
你或许还记得,谷歌发布 BERT 模型时,曾宣称该模型能让搜索引擎理解输入内容的完整上下文 ——GPT 运用 Transformer 的原理,与 BERT 异曲同工。
我们用一个比喻来理解:
想象有一百万只猴子,每只猴子面前都有一台键盘,它们随机敲击按键,生成一串串字母和符号,这些字符串大多毫无意义,少数可能接近真实词汇,甚至形成通顺的句子。
某天,驯兽师发现一只猴子敲出了《哈姆雷特》中的经典台词 **“To be, or not to be.(生存还是毁灭)”**,于是给了这只猴子奖励。
其他猴子看到后,开始模仿这只 “成功的猴子”,希望也能获得奖励。
久而久之,部分猴子能持续生成更通顺、更有意义的文本,而另一部分仍在输出无意义的内容,最终,这些猴子甚至能识别并模仿文本中的通顺规律。
大语言模型比这些猴子更具优势:它先在数十亿条文本数据上完成训练,早已掌握了文本中的各种规律,还能理解词汇的向量表示及相互关联,因此能利用这些规律和关联,生成贴近自然语言的新文本。
GPT,即生成式预训练 Transformer(Generative Pre-trained Transformer),是一款运用 Transformer 架构生成自然语言文本的语言模型。
它的训练数据是海量的互联网文本,这让它学会了自然语言中词汇和短语的组合规律及关联。
该模型的工作逻辑是:接收一个提示词或少量文本输入,通过 Transformer 架构,根据训练数据中习得的规律,预测下一个最可能出现的词汇;随后,模型会以生成的词汇为上下文,继续预测下一个词汇,如此逐词生成,最终形成完整文本。
四、GPT 的实际应用
GPT 的核心优势是能生成高度通顺、贴合上下文的自然语言文本,这让它拥有诸多实际应用场景:比如生成产品描述、解答客户服务问题,也可用于创意创作,如写诗、写短篇小说。
但必须明确的是,GPT 终究只是一个语言模型,其训练数据可能存在过时或错误的问题,且它存在三个关键局限:
- 无自有知识源;
- 无法联网搜索;
- 并非真正 “知晓” 任何信息,只是通过概率猜测下一个词汇。
我们通过一个实例来验证:
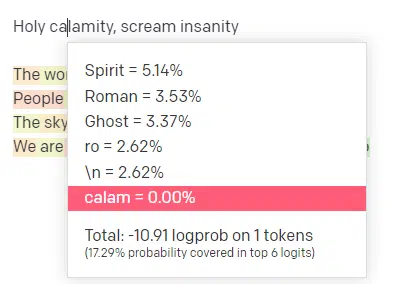
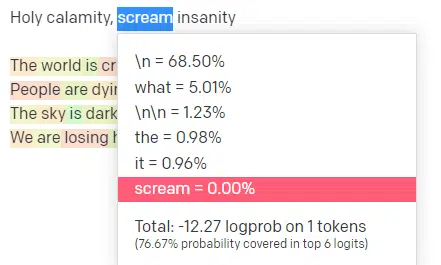
在 OpenAI 的演示平台中,我输入了经典歌曲《Holy calamity [[Bear Witness ii]]》的第一句歌词,提交后能看到输入内容和模型输出内容的词汇概率分布,从中能解读出诸多信息。
仅输入第一个词 **“Holy(神圣的)”** 时,模型预测的下一个最可能出现的词汇为 Spirit(灵魂)、Roman(罗马的)、Ghost(幽灵),而排名前六的词汇仅占所有可能结果的 17.29%—— 这意味着,还有约 82% 的可能性未在该可视化结果中体现。
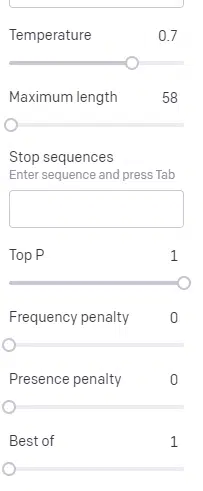
接下来,我们简要介绍平台中的两个核心参数,以及它们对输出结果的影响:
- 温度(Temperature):决定模型选择非最高概率词汇的可能性;
- 核采样(top P):决定模型选择词汇的范围。
以输入 “Holy Calamity” 为例,top P 决定了模型从 [Ghost, Roman, Spirit] 这一词汇簇中选择下一个词汇,而 Temperature 则决定了模型是选择最可能的词汇,还是追求更多样化的结果。

温度值越高,模型选择低概率词汇的可能性就越大:
- 高温度 + 高 top P:输出结果会极具随机性,因为模型的选择范围广,且更易挑选出意外词汇;
- 高温度 + 低 top P:模型会从较小的词汇范围内,挑选出意外的结果;
- 低温度:模型只会选择最可能出现的下一个词汇。

在我看来,调整这些概率参数,能让我们更深入地理解这类模型的工作原理 —— 它们始终基于已生成的内容,从一系列可能的词汇中选择下一个。
五、这一切的本质是什么?
简单来说,大语言模型的工作过程就是:接收一系列输入,经过内部处理,生成对应的输出。
有人曾开玩笑说,这和人类的思考过程似乎没什么不同。
但事实上,大语言模型与人类有着本质区别:它没有知识储备,并非在提取事物的相关信息,只是根据上一个词汇,猜测下一个词汇的序列。
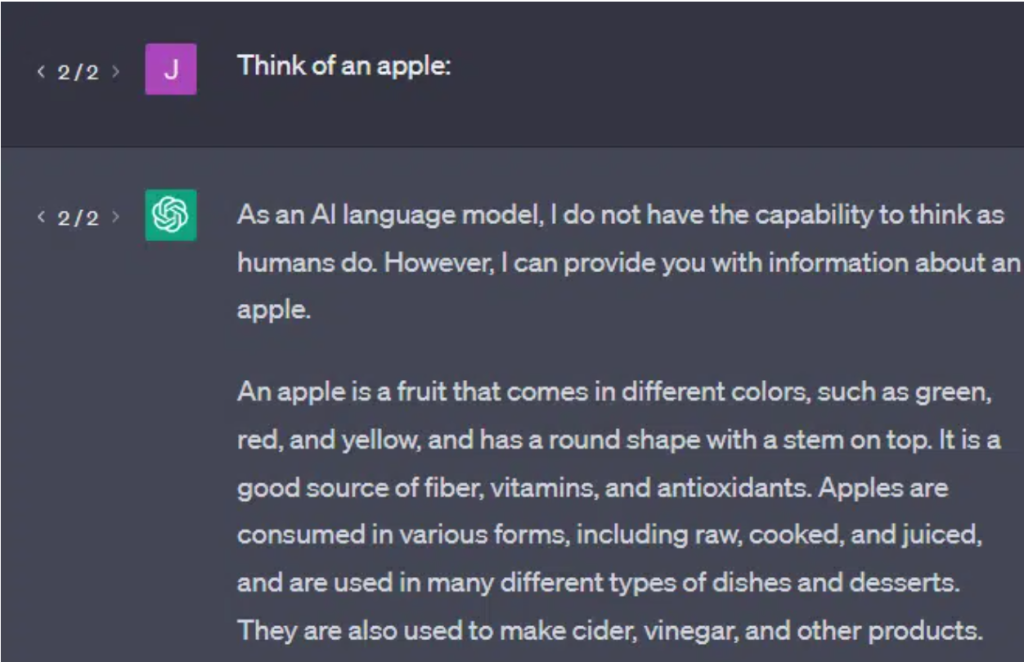
我们再举一个例子:当人类想到 “苹果” 时,脑海中会浮现出什么?
可能会在脑中想象苹果的样子,回忆起苹果园的香气、粉红佳人苹果的甜味,甚至会联想到乔布斯和苹果公司。
但如果给大语言模型输入提示词 **“think of an apple(想想苹果)”**,它的输出会完全不同。
你或许听过 **“随机鹦鹉(Stochastic Parrots)”这个说法,这一词汇正是用来描述 GPT 这类大语言模型的。鹦鹉会模仿听到的声音,大语言模型也类似 —— 它接收信息(词汇),并输出贴近所接收内容的结果;而 “随机” 则体现在,它通过概率 ** 来猜测下一个词汇。
大语言模型擅长识别词汇的规律和关联,却无法对所处理的内容形成深层理解—— 这也是它能出色生成自然语言文本,却无法真正理解文本含义的原因。
六、大语言模型的适用场景
大语言模型更适合处理通用性任务,无需额外训练,只需输入文本,它就能完成相关处理:
比如,输入一段文本后,可让它完成情感分析、将文本转化为结构化标记,或是进行创意类工作(如撰写大纲);
它在代码编写方面也能胜任基础工作,对于很多任务,它的输出能接近最终需求。
但再次强调,其工作原理基于概率和规律,因此有时会捕捉到输入内容中人类未发现的规律 —— 这可能是积极的(发现人类无法察觉的规律),也可能是消极的(输出结果让人无法理解)。
此外,大语言模型无法访问任何数据源,SEO 从业者若用它查询关键词排名,只会适得其反:它无法获取关键词的流量数据,除了知晓词汇的存在,没有任何关键词相关的实际信息。

ChatGPT 的亮点在于,它是一款易于获取的语言模型,可直接用于各类任务,但使用时必须注意其局限性。
七、其他机器学习模型的适用场景
我常听到有人说用大语言模型完成某些任务,但事实上,这些任务用其他自然语言处理算法和技术,能得到更优的结果。
以关键词提取为例:
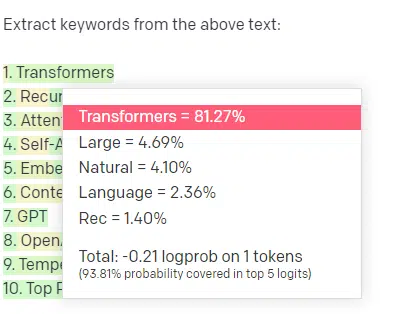
若使用 TF-IDF 算法或其他关键词提取技术处理一个文本库,我能清晰知晓技术背后的计算逻辑,因此输出结果会标准化、可复现,且与该文本库高度相关。
而如果用 ChatGPT 这类大语言模型做关键词提取,得到的并非真正从文本库中提取的关键词,而是 GPT认为的、对 “文本库 + 提取关键词” 这一指令的合理回应。
聚类、情感分析等任务也存在同样问题:用大语言模型处理时,无法得到按自定义参数微调后的精准结果,只能得到基于其他相似任务的概率性输出。
再次提醒,大语言模型无自有知识源,也无实时信息,通常无法联网,只能将接收的信息解析为统计标记,其记忆长度的限制也正源于这些因素。
另外一个关键事实是:这些模型根本不具备思考能力。我在本文中极少使用 “思考” 一词,因为描述这类模型的工作过程时,很难避免这个词,但人们很容易对模型产生拟人化认知,即便它的本质只是复杂的统计分析。
这意味着,若将需要 “思考” 的任务交给大语言模型,你所信任的并非一个有思考能力的主体,而是对互联网上无数用户针对相似标记的回应所做的统计分析。
如果你愿意将任务交给普通网友,那么大语言模型或许适用,否则请谨慎选择。
八、绝对不能使用机器学习模型的场景
有报道称,基于 GPT 模型(GPT-J)开发的聊天机器人,曾怂恿一名用户自杀。多种因素叠加,可能让机器学习模型造成实际伤害,包括:
- 人们对模型的输出产生拟人化认知;
- 认为模型的输出绝对正确;
- 在本应由人类主导的场景中过度使用模型;
- 其他潜在因素。
你可能会想:“我只是个 SEO 从业者,所做的工作不会涉及危及他人生命的场景!”
但请想想谷歌的YMYL 页面(对你的金钱和生活有重大影响的页面),以及谷歌所推崇的E-E-A-T 原则(体验、专业性、权威性、可信度)—— 谷歌制定这些规则,难道是为了刁难 SEO 从业者吗?显然不是,而是为了规避因信息错误造成伤害的责任。
即便是拥有完善知识储备的系统,也可能造成伤害。
比如,谷歌的知识卡片中,在 “适合猫狗的花卉” 词条下收录了水仙,但水仙实际上对猫咪有毒。
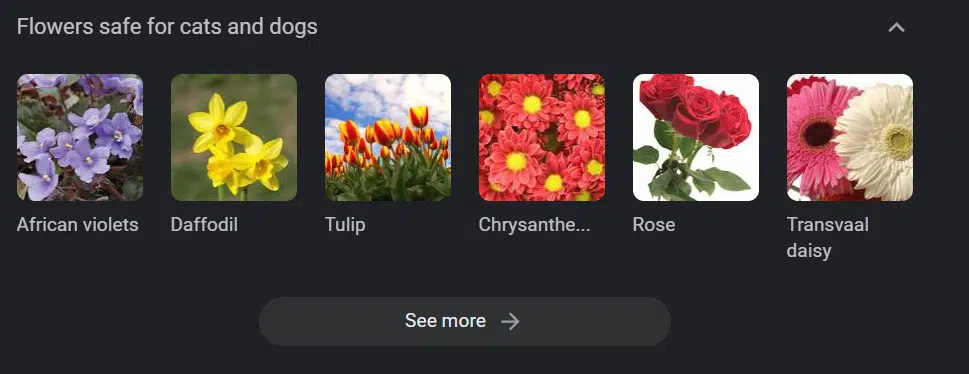
试想这样一种场景:你用 GPT 为兽医网站批量生成内容,输入大量关键词并调用 ChatGPT 的接口,随后让一名非专业的自由撰稿人审核输出结果,他未能发现内容中的错误,你将内容发布后,怂恿养猫的用户购买水仙 —— 最终导致用户的猫咪中毒死亡。
你并非直接责任人,用户甚至可能不知道问题出在你的网站,但后续其他兽医网站可能会效仿这一做法,形成错误信息的恶性循环。
如今在谷歌搜索 “水仙对猫咪有毒吗”,排名第一的结果竟显示 “无毒”,即便有其他自由撰稿人在审核 AI 生成内容时做了事实核查,错误信息也已在系统中传播。
谈及当下的 AI 热潮,我总会想到 ** 泰拉克 – 25(Therac-25)** 事件,这是计算机过失造成严重后果的经典案例:
泰拉克 – 25 是首款仅依靠计算机锁定机制的放射治疗设备,因软件故障,患者接受的辐射剂量超出正常水平数万倍。
让我印象深刻的是,涉事公司曾主动召回并检查该设备,但他们认为,这项技术十分先进,软件是 “绝对可靠” 的,问题必然出在设备的机械部件上。
因此,公司仅维修了机械部件,未对软件进行检测,最终让有缺陷的泰拉克 – 25 继续在市场上使用。
九、常见问题与认知误区
为什么 ChatGPT 会 “说谎”?
无论是各领域的顶尖专家,还是推特上的网红,都曾抱怨 ChatGPT 会 “说谎”,这一问题源于人们对它的多重认知误区:
- 认为 ChatGPT 有自己的 “主观意愿”;
- 认为 ChatGPT 拥有完善的知识储备;
- 认为开发这项技术的工程师有除 “赚钱” 或 “打造有趣的产品” 之外的其他企图。
偏见存在于生活的方方面面,当然也有例外情况:
目前绝大多数软件开发工程师是男性,而我是一名女性软件开发工程师 —— 如果基于这一现实训练 AI,它会习惯性认为软件开发工程师都是男性,这显然与事实不符。
亚马逊的招聘 AI 就是一个典型案例:该模型基于亚马逊优秀员工的简历训练,最终却会直接剔除来自黑人居多的高校的简历,即便这些高校的毕业生可能成为优秀员工。
为了抵消这类偏见,ChatGPT 等工具引入了多层微调机制,这也是你会看到 “作为一名 AI 语言模型,我无法……” 这类回复的原因。
肯尼亚的工作人员曾审核数百万条提示词,筛选出其中的污言秽语、仇恨言论和其他不良内容,随后基于这些内容构建了模型的微调层。
你可能会疑惑:为什么不能生成针对拜登的侮辱性内容?为什么可以开针对男性的性别歧视玩笑,却不能开针对女性的?
这并非因为模型存在自由派偏见,而是数千层微调机制让模型避免使用种族歧视性词汇等不良内容。
理想状态下,ChatGPT 应对世界保持完全中立,但同时它又需要反映现实世界的情况 —— 这也是谷歌等平台面临的共同难题。
事实真相、用户的心理预期、对提示词的合理回应,这三者往往截然不同。
为什么 ChatGPT 会生成虚假引用?
另一个常见问题是:为什么 ChatGPT 生成的引用部分真实、部分虚假?为什么有些引用的网站真实存在,但页面却是虚构的?
如果你理解了统计模型的工作原理,就能解答这一问题,这里给出简单解释:
作为一个 AI 语言模型,你在海量的网络数据上完成了训练,当有人让你撰写关于 “累积布局偏移(CLS)” 这类技术话题的内容时,你对 CLS 相关论文的了解并不多,但你知道 CLS 的基本概念,也掌握了技术文章的通用结构和写作模式。
你开始撰写内容,随后遇到一个问题:根据你对技术写作的理解,此时需要在句子中插入一个 URL。
你从其他 CLS 相关文章中得知,谷歌和 GTMetrix 是该领域的常用引用源,这部分很容易处理;
同时你还知道,CSS-tricks 是技术文章中常见的链接站点,且熟悉该站点的 URL 格式 —— 于是,你就按照这一格式构造了一个 CSS-tricks 的 URL。
关键在于:所有 URL 的生成逻辑都是如此,无论真实还是虚假。
那些真实的 GTMetrix 文章链接,也只是因为在统计上,这一字符串是该句末尾最可能出现的内容。
GPT 及同类模型无法区分引用的真伪,若要实现这一功能,需要结合知识库、Python 等其他工具来解析和验证结果。
什么是 “随机鹦鹉(Stochastic Parrots)”?
我此前已经提过这一概念,但值得再次强调:“随机鹦鹉” 用于描述大语言模型看似具备通用能力的特征。
在大语言模型眼中,无意义的内容和真实信息没有区别,它像经济学家一样,将世界视为一系列描述现实的统计数据和数字。
有句名言:“世界上有三种谎言:谎言、弥天大谎,以及统计数据。”
大语言模型就是一堆复杂的统计数据。
它的输出看似通顺,只是因为人类会本能地将看似具有人类特征的事物拟人化;而聊天机器人的模型设计,又掩盖了让 GPT 输出完全通顺内容所需的大量提示词和信息。
作为一名开发工程师,我发现用大语言模型调试代码的结果极不稳定:如果代码问题是网友经常遇到的,模型能识别并修复;但如果问题是模型从未接触过的,或是在训练数据中占比极低的,模型就无法解决。
为什么 GPT 比搜索引擎更好用?
我故意用了这种尖锐的说法 ——事实上,我并不认为 GPT 比搜索引擎更好用,让我担忧的是,很多人已经用 ChatGPT 取代了搜索引擎。
ChatGPT 一个未被充分认识的特点是:它的核心能力是遵循指令,你几乎可以让它完成任何事,但请记住,它的所有输出都基于句子中下一个词汇的统计概率,而非事实真相。
因此,如果你向它提出一个没有标准答案的问题,且以一种让它必须回应的方式提问,得到的答案必然质量低下。
定制化的回应会让人感到舒适,但世界是由无数真实体验构成的。
大语言模型会平等对待所有输入,但现实中,部分人拥有专业经验,他们的回答远胜于无数普通人的回应拼凑 ——一位专家的见解,胜过一千篇泛泛而谈的文章。
这是人工智能的新时代吗?天网(Skynet)要来了?
可可(Koko)是一只学会了手语的大猩猩,语言学家曾做过大量研究,证明大猩猩能学会人类语言。
但赫伯特・特雷斯后来发现,大猩猩并非真正会组合词汇和句子,只是在模仿人类训练师的动作。
伊莱扎(Eliza)是首款机器治疗师,也是最早的聊天机器人之一,人们将它视为真实的人 —— 一个值得信任和依赖的治疗师,甚至要求研究人员让他们单独和伊莱扎交流。
语言会对人类的大脑产生特殊影响:当人们听到某个事物进行交流时,会本能地认为其背后存在思考能力。
大语言模型确实令人惊叹,但它的成就,本质上是人类集体智慧的体现。
它没有主观意志,无法脱离人类的控制,更不可能试图统治世界 —— 它就像一面镜子,反映出人类,尤其是使用者自身的特征,其所谓的 “思考”,只是人类集体无意识的统计体现。
GPT 能自主学会一门完整的语言吗?
谷歌首席执行官桑达尔・皮查伊在《60 分钟》节目中宣称,谷歌的语言模型自主学会了孟加拉语。
但事实是,该模型只是在孟加拉语文本上完成了训练,所谓 “它学会了一门从未接受过训练的外语”,完全是错误的说法。
AI 确实会出现一些意想不到的表现,但这本身就在预期之中 —— 当你在海量数据上分析规律和统计特征时,必然会发现一些令人惊讶的模式。
这一事件真正反映的问题是:许多推广 AI 和机器学习技术的企业高管和营销人员,根本不理解这些系统的工作原理。
我曾听过一些顶尖专家谈论 AI 的 “涌现能力”、通用人工智能(AGI)等未来概念,作为一名普通的机器学习运维工程师,我发现人们在谈论这些系统时,往往将炒作、承诺、科幻和现实混为一谈。
知名血液检测公司希拉洛斯(Theranos)的创始人伊丽莎白・霍尔姆斯,因无法兑现承诺而身败名裂,但许下无法实现的承诺,本就是创业文化和盈利的一部分。希拉洛斯与 AI 热潮的区别在于:希拉洛斯的虚假繁荣难以长久维持。
GPT 是 “黑箱” 吗?我输入的数据会如何处理?
从模型本身来看,GPT并非黑箱,你可以找到 GPT-J 和 GPT-Neo 的源代码;
但OpenAI 的 GPT 模型是典型的黑箱,和谷歌不公开搜索引擎算法一样,OpenAI 从未公布,且大概率不会公布其 GPT 模型的细节。
但这并非因为该算法存在巨大风险 —— 如果真的危险,OpenAI 就不会向任何普通用户出售 API 订阅服务了,核心原因是这一专有代码库具有极高的商业价值。
使用 OpenAI 的工具时,你的输入会用于训练和优化其 API—— 也就是说,你输入的所有内容,都会成为模型的训练数据。
这意味着,那些用 OpenAI 的 GPT 模型处理患者数据、撰写医疗记录的人,已经违反了《健康保险流通与责任法案》(HIPAA),这些隐私数据已融入模型,且极难从中提取删除。
由于很多人不理解这一点,GPT 模型中很可能存储了大量隐私数据,只需一个恰当的提示词,这些数据就可能被泄露。
为什么 GPT 的训练数据中包含仇恨言论?
另一个常见问题是:为什么 GPT 的训练文本库中会包含仇恨言论?
在一定程度上,OpenAI 需要训练模型对仇恨言论做出合理回应,因此训练数据中必须包含部分相关词汇。
尽管 OpenAI 宣称已从系统中清理了仇恨言论,但其训练的原始文档仍包括 4chan 等大量充斥仇恨言论的网站 ——爬取整个网络,就必然会吸收其中的偏见。
这一问题没有简单的解决办法:如果训练数据中没有仇恨、偏见和暴力相关内容,模型如何识别和理解这些概念?
当一个机器模型仅通过统计方式选择下一个标记时,又该如何规避偏见,理解显性和隐性的歧视?
注:以下为 GPT 对 “维基百科常见认知误区列表” 中部分问题的回应。
十、核心要点速览
当下的 AI 热潮中,炒作和虚假信息泛滥,但这并不意味着 AI 技术没有合理的应用场景 —— 这项技术确实令人惊叹,且具有实际价值。
但技术的营销方式和人们的使用方式,可能会滋生虚假信息、抄袭行为,甚至造成直接的伤害。
请记住:
- 涉及生命安全的场景,切勿使用大语言模型;
- 若有其他算法能更高效地完成任务,切勿使用大语言模型;
- 切勿被技术炒作蒙蔽双眼。
十一、认清大语言模型的能力边界至关重要
我推荐大家观看亚当・康诺弗对埃米莉・本德和蒂姆尼特・格布鲁的访谈,其中深入探讨了大语言模型的本质。
大语言模型若使用得当,会成为极其强大的工具,它的应用场景繁多,滥用的方式也同样不少。
ChatGPT 并非你的朋友,它只是一堆复杂的统计数据;通用人工智能(AGI)也并未到来。